Bravo, vous avez réussi à installer Apache sur une distribution Debian.

Bravo, vous avez réussi à installer Apache sur une distribution Debian.
Voilà un très long billet sur les tests de charge
Le test de capacité a pour objectif de donner sur une plateforme donnée une référence des réactions d’un applicatif soumis à la charge des utilisateurs.
Le test met en oeuvre une charge correspondant à une utilisation normale de l’application par un nombre déterminé d’utilisateurs. Puis le nombre d’utilisateurs est progressivement augmenté pour atteindre les limites du système.
Ce test permet généralement d’identifier les goulets d’étranglement d’un applicatif et aussi de vérifier que l’évolution des temps de réponse correspond aux cahiers des charges.
Les tests d’évolutivité sont effectués pour permettre de mesurer une montée en charge d’une infrastructure et déterminer l’évolution à apporter à l’infrastructure pour garder le même service aux utilisateurs.
Les tests d’évolutivité sont aussi effectués pour mesurer l’impact d’une augmentation/baisse du matériel sur le temps de réponse aux utilisateurs.
La population totale est le nombre total d’utilisateurs dans l’entreprise.
Celle valeur nous donne la borne haute pour nos tests de charge.
Dans le cas de APPLIXXX, 3 000 utilisateurs
Actuellement 30 utilisateurs
Evolution à tester vers 3 000 utilisateurs
Le nombre simultané d’utilisateurs s’obtient en prenant en compte deux paramètres : le nombre d’utilisateurs potentiels et le taux d’utilisation journalier de l’application.
Nous pouvons mesurer le pourcentage de temps passé à utiliser l’application dans une journée pour obtenir le facteur. Facteur = 1 / %temps passé.
Pour aider dans les simulations de charges, nous pouvons choisir un facteur d’utilisateurs simultanés de 10
Soit NUtilS = NUtilP / 10
Dans le cas de APPLIXXX, un facteur 10 sera utilisé.
Ce chiffre représente à un instant t le nombre d’utilisateurs qui accède à une même information dans l’application en partant du nombre d’utilisateurs actuellement connecté soit NUtilS.
En général, nous pouvons prendre un facteur 10 entre le nombre d’utilisateurs simultanés et le nombre d’utilisateurs concurrents.
Soit NUtilS = NUtilC / 10
Dans le cas du test de charge de APPLIXXX, un facteur 10 est utilisé.
Le profil utilisateur regroupe les personnes effectuant strictement les mêmes tâches sur l’application.
Dans le cas de APPLIXXX, les différents profils utilisateurs sont les suivant :
Si les profils sont peu éloignés les un des autres, il est possible de les regrouper. Ceci a pour effet de diminuer la durée de la mise en place de la phase de test de charge.
Le groupe de profil résultant comprendra l’union de tous les profils pour n’exclure aucun cas.
Dans le cas de APPLIXXX, deux profils seront utilisés :
Une simulation des actions de l’utilisateur doit être faite pour définir le scénario correspondant au groupe de profil. L’enregistrement est fait sur Visual Studio 2005 Team Suite par le module Web Test. Le scénario est enregistré manuellement. Ce scénario doit être ensuite être adapté pour prendre les différentes entrées saisies de façon aléatoire en balayant bien l’ensemble des données possibles.
Déterminer si les traitements sont continus ou si ils sont intermittent. Par exemple bilan journalier ou mensuel impliquant une charge spécifique
Déterminer si au fur et à mesure de la journée, les traitements sont les mêmes. Par exemple : applicatif utilisé en saisie le matin et l’après midi avec une clôture le midi et le soir.
La durée du test doit être représentative de l’utilisation des serveurs au quotidien. Les tests doivent être longs pour simuler au mieux les différents processus de mise en cache qui peuvent intervenir ( Cache Navigateur, Cache Serveur Application, Cache base de données, Cache Disque, … ). Le temps de pensé doit aussi être mis en place pour simuler le temps de réflexion de l’utilisateur.
Dans le cas de APPLIXXX, la durée du test ne devra pas être inférieure à 3 minutes par palier d’utilisateurs.
Prendre en compte les évolutions estimées du nombre d’utilisateurs par rapport à la durée de vie de l’application.
Dans le cas de APPLIXXX, l’évolution sera estimé à un nombre d’utilisateur de 3 000.
Distribution des utilisateurs par rapports aux différents profils.
Dans le cas de APPLIXXX, 30% Création , 70%, Consultation
Cela représente la taille de départ des données ( base ou autres ) à prendre en compte au début de la phase de test de charge.
C’est le volume minimum des données à utiliser pour effectuer les tests. Nous devons absolument faire nos tests de charges sur des données qui ont un volume très proche de celle de production car ce facteur influence énormément les performances.
Le nombre d’enregistrement et la distribution des enregistrements doit être respecté par rapport aux données de production.
Ces valeurs nous donnent des indicateurs de d’évolution des données dans le temps.
La quantité de modification des données existantes, n’est pas un facteur très important car il n’y a pas d’évolution de volume des données ou très faible.
Par contre, la création de contenu influence les performances. Notre test devra prendre en compte le volume de données de départ plus le volume qui va être créé sur la durée de vie présumé de l’application.
Dans le cas de APPLIXXX :
Population = 3 000
Aujourd’hui
Evolution
Répartition des profils
Paliers et durées
| Désignation | Temps | Action |
| Recherche de la contrepartie | 5 » | Cliquer sur « Recherche contrepartie » |
| Affichage de la liste des contreparties | 5 » | Après avoir renseigné le pays, type et nom Cliquer sur « GO » |
| Consultation contrepartie | 5 » | Cliquer sur la loupe |
| Page Notation | 5 » | Cliquer sur la « Notation » |
| Voir la grille | 5 » | Cliquer sur la « Voir les Grilles » |
| Consultation grille | 5 » | Cliquer sur la loupe |
| Créer grille | 7 » | Cliquer sur la « Commencer » |
| Calculer | 10 » | Cliquer sur la « Calculer » |
| Valider | 10 » | Cliquer sur la « Valider » |
Nous attirons votre attention sur les critères d’utilisation maximum des serveurs. Ces critères sont importants à prendre en compte pour éviter les perturbations de service lors d’une surcharge temporaire. Les valeurs sont données dans les listes de compteur à surveiller lors d’un test de charge.
Les utilisations du processeur dans les périodes de forte activité ne doivent pas dépasser 80% temps processeur sur une période d’échantillonnage de 30 minutes.
En moyenne sur une journée, le temps processeur ne doit pas excéder 50 % à 60%.
Le compteur mémoire pages/s doit en moyenne sur la journée avoir une valeur inférieure 20.
Le compteur PhysicalDisk : % Disk Time. Il s’agit du pourcentage de temps écoulé pendant lequel le lecteur du disque sélectionné est occupé à traiter des requêtes de lecture et d’écriture. Associé au compteur Disque physique : taux moyen de file d’attente du disque, il constitue un indicateur clé d’un goulet d’étranglement d’un lecteur de disque. Notez que nous devons exécuter l’utilitaire de ligne de commande Diskperf –y avant de rechercher les compteurs du disque sur Windows . Cette donnée peut être faussée par l’utilisation de carte contrôleur avec cache intégré. En général, cette valeur ne doit pas excéder 50 %.
La mesure des IO/sec sur les disques. Un élément très important de performance est le système disque. Pour effectuer des mesures correctes, il faut mesurer le nombre d’IO/sec maximum que notre système disque supporte. Il dépend du nombre de disque, de leur vitesse (rpm), de leur capacité et aussi de la répartition sur les partitions. Pour effectuer ces mesures, il est nécessaire d’utiliser un logiciel de stress disque et un outil de monitoring adapté à la baie de stockage. Un utilitaire type « Bart’s Stuff Test 5 » sous windows peut permettre de simuler la charge disque et de connaître le maximum supporté par le système disque. Sous HPUX nous pouvons utiliser HPUX Workload Manager. En production, les IO/sec doivent être au maximum de 80% des I/O /sec maximum possible du système. Dans le cas contraires nous devons augmenter le nombre de disques durs ou changer de technologie. Le compteur sur HPUX est GBL_DISK_PHYS_IO_RATE.
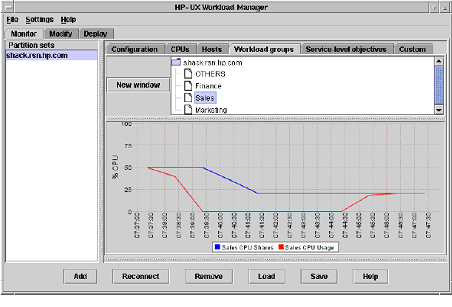
Figure 31 HP UX WorkLoad Manager
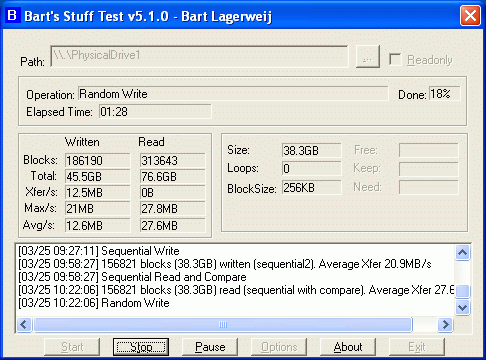
Figure 32 Bart’s Stuff Test
Le compteur PhysicalDisk : Avg. Disk Queue Length. Si le disque n’est pas suffisamment rapide pour suivre le rythme des requêtes de lecture et d’écriture, ces dernières sont placées dans la file d’attente. Si le compteur disque physique présente les caractéristiques suivantes : PhysicalDisk:% Disk Time
supérieur à 85% et Avg. Disk Queue Length supérieur à deux ; et si l’activité du disque n’est pas causée par un manque de RAM, alors le goulet d’étranglement peut être constitué par le disque. Les autres compteurs qui peuvent être utilisés pour analyser le trafic du disque comprennent le compteur PhysicalDisk : Disk Reads /sec ; le compteur PhysicalDisk : Disk Writes/sec ; et le compteur Base de données : Log Writes / sec.
Nous devons donc songer à ajouter des lecteurs physiques au système de disques, tels qu’un système RAID. Ils permettront d’accroître le nombre de piles de disque capables de lire ou d’écrire, ainsi que d’accélérer la vitesse de transfert des données.
Le compteur System : % Processor Time. Il s’agit du pourcentage de temps pendant lequel les processeurs sont occupés. Lorsque ce compteur reste constamment entre 80 % et 100 %, il constitue un indicateur clé d’un goulet d’étranglement de l’unité centrale de traitement. Nous installons alors des processeurs supplémentaires. Sur HPUX le compteur à utiliser est GBL_CPU_TOTAL_UTIL.
Le compteur System: Processor Queue. Il s’agit du décompte instantané (et non d’une moyenne) du nombre de threads placées dans la file d’attente jusqu’à ce que le processeur parvienne en fin de cycle. Des longueurs de file d’attente constamment supérieures à deux indique généralement que le processeur est saturé. Nous installons des processeurs supplémentaires. Dans le cas d’un serveur quadri-processeur, il faut tenir compte de la file d’attente au maximum de 2 par processeur soit 8 au total. Sur HPUX le compteur à utiliser est GBL_CPU_QUEUE
Le compteur Processor : % DPC Time. Il s’agit du pourcentage de temps où le processeur dit : « je suis occupé, je traiterai ça plus tard en priorité faible ». Si cette valeur est à plus de 50% alors nous pouvons suspecter un problème de carte réseau. Sur HPUX le compteur est GBL_RPC_WAIT_PCT.
Le compteur Processor : Interrupts/sec. La valeur d’Interrupts/sec pour l’objet Processeur ne doit pas augmenter soudainement avec une augmentation de l’activité système. Cela signifierait un problème de matériel.
Si le % Processor Time est supérieur à 90% et si Interrupts/sec excède 15%, nous vérifions les drivers pour s’assurer qu’ils sont bien écrits ou sinon nous upgradons le CPU.
Sur HPUX le compteur utilisé est
GBL_CPU_INTERRUPT_UTIL.
Le compteur Process : Working Set. Nombre de Mo de mémoire actuellement utilisé par tous les processus en cours sur le serveur. La valeur de ce compteur doit être > 10% de la mémoire serveur. Sur HPUX le compteur est PROC_MEM_RES
Le compteur Process : Private Bytes. Il s’agit du nombre actuel d’octets que ce processus a alloué et qui ne peut être partagé avec d’autres processus. Si le système connaît une baisse progressive de ses performances, ce compteur peut être un bon indicateur de fuites de mémoire. Nous informons les développeurs du projet.
Sur HPUX le compteur est PROC_MEM_PRIVATE_RES. Attention il faut activer l’option process memory region pour avoir des valeurs en retour.
Le compteur Thread:Context Switches/sec. Il mesure le nombre maximal de threads, ou paquet de threads, par processeur. Nous devons surveiller ce compteur afin de nous assurer que nous ne créons pas un trop grand nombre de commutateurs de contexte, car dans ce cas la quantité de mémoire qui leur est dédiée annulerait le bénéfice des threads supplémentaires et nos performances diminueraient au lieu d’augmenter. Toute valeur supérieure à 15 000 commutateurs par seconde doit être considérée comme excessive. Sur HPUX le compteur est GBL_CPU_CSWITCH_UTIL.
Le compteur Paging File: % Usage. Il s’agit du compteur qui donne l’utilisation du fichier d’échange pagefile. Si le compteur dépasse le seuil de 70%, nous avons un goulet d’étranglement. Une solution consiste à séparer le fichier sur plusieurs disques et à en augmenter la taille. Sur HPUX le compteur est PROC_MEM_VIRT.
Le compteur Memory Page /sec. Il s’agit du compteur donne le nombre de pages récupérées sur le disque lorsque celles-ci sont absentes du jeu de pages de travail. Ce compteur peut faire de brusque montée mais il doit être en moyenne à une valeur inférieure à 20 pages par seconde. Sur HPUX il n’y a pas d’équivalent direct.
Le compteur Memory: Page Faults / Sec. Il s’agit de la somme des pages fault hard et soft. Les pages fault soft sont les données qui sont trouvées quelque part dans la mémoire. Par exemple, quand l’application Word ouvre le correcteur orthographique, et que Outlook demande lui aussi à l’utiliser, le correcteur est déjà en mémoire , il n’y a donc pas besoin d’accéder au disque. Les pages fault hard sont générée quand les données sont chargées à partir du pagefile.sys sur le disque. Des taux soutenus de pages fault hard dépassant cinq défaillances par seconde indiquent clairement que le système ne dispose pas de suffisamment de mémoire RAM. Les autres compteurs Mémoire capables d’indiquer un goulet d’étranglement de la mémoire sont : Pages Inputs /sec, Pages Reads /sec et Pages /sec. Sur HPUX le compteur est PROC_MEM_VFAULT_COUNT.
Le compteur Memory : Available Bytes. Il mesure la mémoire physique totale disponible pour le système d’exploitation et la compare à la mémoire nécessaire à l’exécution de l’ensemble des processus et des applications sur votre serveur. Tentez de garder au moins 10 % de la mémoire disponible pour les pics d’activité. Gardez à l’esprit que par défaut l’application Microsoft IIS 5.0 utilise jusqu’à 50 % de la mémoire disponible pour sa mémoire cache, laissant le reste de l’espace disponible aux autres applications exécutées sur l’ordinateur serveur. Si cet espace reste constamment en dessous de 4 Mo, il est temps de songer à installer de la mémoire supplémentaire. En général, une valeur supérieure à 10% de la taille de la mémoire totale est recommandée. Sur HPUX le compteur est GBL_MEM_UTIL qui est la quantité de mémoire utilisée donc il faudra soustraire ce chiffre à la mémoire totale su système pour correspondre à windows.
Le compteur Cache: Data Map Hits %. Il s’agit du pourcentage de données dans le cache qui peuvent être récupérées sans avoir besoin d’un accès au disque. Il mesure, le volume de page de données déjà dans la mémoire physique. Sur HPUX, le compteur est GBL_CACHE_HIT_PCT
Le compteur Network Interface: Bytes Total/sec. Ce compteur donne le volume de données envoyées et reçues sur le réseau. Attention ce compteur est en octets/sec. Sur HPUX on utilisera alors la somme de deux compteurs BYNETIF_OUT_BYTE_RATE + BYNETIF_IN_BYTE_RATE.
Le compteur Network Interface: Bytes Sent/sec. Ce compteur utilisé avec le compteur précédent permet de connaître la répartition du flux en Sortie par rapport au total. Sur HPUX le compteur est BYNETIF_OUT_BYTE_RATE en Ko.
Le compteur Network Interface: Bytes Received/sec. Ce compteur utilisé avec le compteur Bytes Total/sec permet de connaître la répartition du flux en Entrée par rapport au total. Sur HPUX le compteur est BYNETIF_IN_BYTE_RATE en Ko.
Le compteur Network Interface: Current Bandwidth. Le compteur de bande passante donne la valeur du débit maximum sur le lien réseau. Attention ce compteur est en bit/sec. La première comparaison a faire est celle du Bytes Total/sec et du Current Bandwidth, en n’oubliant pas les unités. Bytes / Sec * 8 par rapport à Current Bandwidth. Un goulet d’étranglement sera détecté si le rapport est supérieur à 60 %. Sur HPUX le compteur est BYNETIF_NET_SPEED
Les compteurs Process:Thread Count:Inetinfo ,
Thread:% Processor Time:Inetinfo=>Thread# ,
Thread:% Processor Time:Mtx=>Thread# ,
Thread:Context Switches/sec:Inetinfo=>Thread# ,
Thread:Context Switches/sec:Mtx=>Thread#. Ces compteurs servent à calibrer le nombre de threads nécessaires par rapport au changement de contexte et aux interruptions. Si les threads sont en permanence occupés, mais n’utilisent pas tout le temps processeur alors les performances peuvent être améliorées en créant plus de threads. Néanmoins, si tous les threads sont occupés et que le temps processeur est proche de son maximum, nous devons penser à distribuer la charge sur un nombre plus important de serveurs plutôt que d’augmenter le nombre de threads. Si nous augmentons la taille du pool de thread, nous devons aussi surveiller les compteurs Thread:Context Switches/sec:Inetinfo=>Thread#, Thread:Context Switches/sec:Mtx=>Thread#, et System:Context Switches/sec. L’augmentation du nombre de threads peut augmenter le nombre de changement de contexte à un point tel que les performances peuvent alors chuter.
Le compteur IIS global : cache hits percent. Ce compteur doit être aussi élevé que possible.
Le compteur Web service : Bytes total /sec. Ce compteur doit être aussi élevé que possible.
Le compteur ASP : request wait time. Ce compteur doit être aussi bas que possible.
Le compteur ASP : transactions per second. Ce compteur doit être aussi haut que possible.
Les compteurs ASP (Active Server Page) et les Requêtes dans la file d’attente. Ces compteurs surveillent le nombre de requêtes attendant la réponse d’un service. Si le nombre indiqué par le compteur Requêtes dans la file d’attente varie considérablement au cours d’un stress et si, dans le même temps, l’utilisation du processeur demeure relativement basse, cela indique que le script appelle un objet COM recevant un nombre d’appels supérieur à ce qu’il est capable de gérer. Dans ce cas, l’objet COM appelé dans le ASP constitue généralement le goulet d’étranglement. Nous devons le notifier aux développeurs du projet.
Le compteur ASP.NET : Application Restarts. Ce compteur doit être stable. Un changement de valeur indique que l’application a redémarrée cela peu venir un plantage de m’application ou d’une surcharge du serveur. Si il n’y a pas de variation c’est le fonctionnement normale de l’application.
Le compteur ASP.NET : Request Execution Time. Ce compteur donne le temps, en millisecondes, qu’il a fallut pour générer la dernière page demandée et ensuite pour la transmettre à l’utilisateur. Ce compteur va nous permettre de noter l’amélioration des performances lors de la montée en charge de l’application lors de paramétrage ou d’optimisation horizontale ou verticale. Si ce compteur montre une valeur plus faible que la valeur de la ligne de base alors la montée en charge de l’application est possible car les performance ont été augmentées. Si cette valeur augmente avec l’augmentation de la charge, nous avons une influence directe de la charge sur le temps de réponse.
Le compteur ASP.NET : Requests Queued. Ce compteur donne le nombre de requêtes en attente. Si une augmentation apparaît avec l’augmentation de la charge utilisateur cela veut dire que nous avons atteint le nombre maximal de requêtes concurrentes que sait traiter le système. La valeur maximale par défaut de la file d’attente est de 5000 requêtes.
Le compteur ASP.NET : State Server Sessions Active : Il s’agit du compteur du nombre de session active dans ASP.NET. Donc le nombre d’utilisateurs actuellement sur le serveur. Par défaut le timeout d’une session est de 20 minutes. Nous pouvons baisser ce timout pour libérer de la mémoire et augmenter le nombre d’utilisateurs pris en charge sur le serveur. Ce compteur doit être examiné en même temps que le compteur Worker Set.
Le compteur ASP.NET : Worker Process Restarts. C’est une valeur à surveiller importante. Elle donne une indication sur les redémarrage des processus de travail. Ceux ci redémarrent en cas de défaillance. Cette valeur ne doit augmenter.
Le compteur ASP.NET Applications : request/sec . Ce compteur affiche le charge actuelle de traitement de l’application. Plus ce chiffre est élevé plus la charge de la machine est importante. Quand nous analysons les performance sous une charge générée, ce compteur permet de vérifier que les requêtes arrivent aussi vite que nous les envoyons. Si le nombre de requêtes par secondes tombe au dessous du nombre de requêtes générées, une file d’attente apparaît. Cela signifie que le taux maximum de requêtes a été atteint et même dépassé. Ce compteur peut aussi s’avérer utile lors de l’utilisation normale du serveur pour en déterminer la charge.
Le compteur Process : Working Set: aspnet_wp. Ce compteur nous donne la quantité de mémoire effectivement utilisé par ASP.NET pour travailler. C’est un paramètre important pour les développeurs qui donne la consommation de mémoire. Nous pouvons réduire cette valeur en ajustant la valeur de la période de timeout sur les sessions.
Le compteur Process : % Processor Time : aspnet_wp. Ce compteur est le plus important pour déterminer la charge sur une application .NET. Ce pourcentage est en augmentation lors de l’augmentation de la charge. Un ratio peut en être déduit pour estimer la charge maximum supporté par le serveur. Une autre méthode est de pousser le test jusqu’à ce que cette valeur arrive à 60%. Cette valeur de 60% est le maximum acceptable pour une utilisation confortable du serveur.
Le compteur System : % CPU Time. Si le CPU reste très bas cela veut dire que nous avons un problème de verrou ou de blocage qui empêche l’application de fonctionner correctement. Il faut donc surveiller cette valeur pour qu’elle suive la charge en utilisateur.
Le compteur .NET CLR Memory :% Time in GC.
Ce ratio doit être faible environ 5%en moyenne. Si ce temps est plus élevé, nous pouvons suspecter qu’il y a beaucoup de lecture et d’écriture de bloc de buffer qui sont effectués. Cela peut venir de création/suppression de donnée régulière. L’optimisation possible est au niveau du code en changeant les paramètres d’allocation mémoire. Par contre, il n’est pas rare d’avoir des pics d’activité.
Le compteur.NET CLR Exceptions :# of Exceps Thrown. Ce compteur ne doit pas augmenter. Si il augmente les performances baissent. Il sert donc à déterminer la charge maximale d’un serveur.
Le compteur Base de données–Lock : Lock wait /sec. Un nombre élevé de verrous de blocage peut indiquer la présence d’un point névralgique dans la base de données. Informez-en les développeurs du projet.
Le compteur Process: Working Set:sqlserver. Ce compteur nous donne la quantité de mémoire utilisée par SQL Server. Si cette valeur est en permanence largement inférieure à la valeur fixée dans les options du serveur SQL (MIN SERVER MEMORY) alors le serveur à trop de mémoire. Dans les autres cas, il faut penser à ajouter de la RAM et à augmenter la valeur de MAX SERVER MEMORY.
Le compteur SQL Server: Memory Manager: Total Server Memory (KB). Quand la mémoire total du serveur SQL atteint le niveau de la mémoire totale du serveur, cela veut dire que SQL Server se plaint de ne pas avoir assez de mémoire.
Le compteur SQL Server: Buffer Manager: Buffer Cache Hit Ratio. Il s’agit du pourcentage d’occurrences où le serveur de Base données trouve les données dans son cache, au lieu de devoir accéder au disque. Un indice de correspondance de cache inférieur à 80 % indique que le serveur ne dispose pas de suffisamment de RAM. Ceci peut se produire même lorsque le système dispose d’une grande capacité de RAM, si un pourcentage insuffisant a été allouée au serveur de base de données. Une valeur standard doit être située dans la plage des 90%.
Le compteur Process: Page Faults/sec :sqlserver. Ce compteur déjà expliqué précédemment mais ici utilisé pour l’instance SQL serveur permet de connaître l’utilisation de la mémoire dédié à la base de données.
Le compteur SQLServer:General Statistics:User Connections. Ce compteur donne le nombre de client connectés sur le serveur de base de données.
Le compteur SQLServer:SQL Statistics :Batch Request/sec. Ce compteur nous permet de mesurer la charge de travail donnée au serveur SQL.
Le compteur SQL Server: Databases <database instance>: Log Flush Waits Times. Le serveur SQL doit attendre que le sous-système disques ait fini ses entrées sorties dans les fichiers de LOG à chaque transaction pour qu’elle soit validé. Il est important que les disques contenant les LOG de SQL serveur aient suffisamment de capacité E/S pour anticiper les la charge sur le journal de transaction.
La méthode qui consiste à contrôler la file d’attente associée avec les fichiers de LOG est différente de celle pour les bases. Les compteurs à surveiller sont SQL Server: Databases <database instance>: Log Flush Waits Times et SQL Server: Databases <database instance>: Log Flush Waits/sec pour vérifier si des requêtes d’écriture de log sont en attente du sous système disque pour se finir.
Le compteur Buffer NoWait Ratio. Il s’agit du taux auquel se produisent les requêtes pour un buffer spécifique immédiatement disponible. Cette valeur doit être supérieure à 90%.
Le compteur Buffer Cache Hit Ratio. Il s’agit du taux représentant le pourcentage de non attente pour les données. Les données sont actuellement en mémoire et le serveur utilise le cache pour effectuer ses traitements. Nous devons vérifier que cette valeur est toujours au dessus de 90%. Dans le cas contraire, il faut augmenter la mémoire allouée au serveur Oracle et/ou la mémoire système.
Le compteur Latch Hit Ratio. C’est le ratio du nombre total de verrous manqués par rapport au nombre de verrous obtenus. Une valeur faible de ce ratio indique un problème de verrou et au contraire une valeur élevée indique un fonctionnement correct. Cependant, ce ratio peut masquer même si il est élevé un problème sur un verrou spécifique. Il faut donc toujours investiguer sur tous les verrous. En fonctionnement standard le ratio doit être supérieur à 90%.
Le compteur Library Cache Hit Ratio. Il s’agit de la mesure du rapport entre le nombre de chaîne SQL à analyser en mémoire qui sont déjà dans la bibliothèque de cache(Soft Parse) par rapport à celle qui doivent être analysées, validées, et dont on doit fabriquer le plan d’exécution( Hard Parse). La bibliothèque de cache configurée par la valeur shared_pool_size sert à diminuer le hard parse. Ce ratio doit être supérieur à 90%.
Le compteur Redo NoWait Ratio. Il représente le pourcentage d’entrée redo qui ont de l’espace disponible immédiatement dans le journal de redo. Ce pourcentage est calculé de la façon suivante : 100 x (1- (redo log space requests/redo entries). Il devra rester supérieur à 90%.
Le compteur In-memory Sort Ratio. Pourcentage de tri (depuis les clauses ORDER BY ou les constructions d’index) qui est fait du disque par rapport à la mémoire. Les tris disques sont fait depuis le tablespace TEMP, qui est des milliers de fois plus lent que la RAM. Ce taux doit être proche des 90%. La variable sort_area_size peut être ajustée pour régler ce taux.
Ici nous devons mettre les différents scénario que nous devons jouer ainsi que les paramètres de base de chaque scénario.
Pour APPLIXXX
Scénario 1
Consultation de grilles.
Scénario 2
Saisie de grilles.
Protocole de test
Exécution du test composé des différents scénarii sous Visual Studio 2005 Team Suite. Nous utiliserons la base SQL 2005 Express locale sur le poste de travail qui sert à faire le générateur de test.
Nous effectuons une trace système sur chaque machine de l’architecture entrant dans le moniteur de performance sur les machines Windows ou équivalent sur les machines Unix Glance Plus Pak (une combinaison de GlancePLUS et MeasureWare).
|
Modèle de charge |
||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Figure 41 Modèle de charge |
||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||
Charge de 0 à 100 utilisateurs donc une simulation de 0 à 1000 utilisateurs réels.
La charge est modélisée avec des paliers pour laisser le temps aux systèmes de se stabiliser.
La charge réseau ne montre pas de limitation du coté client de test.
|
Système |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Figure 42 Charge Système |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Le client utilisé pour les tests a une mémoire vive assez faible (512 Mo). Celui-ci a suffit à faire fonctionner le test mais il y a eu le déclenchement des alertes.
Système
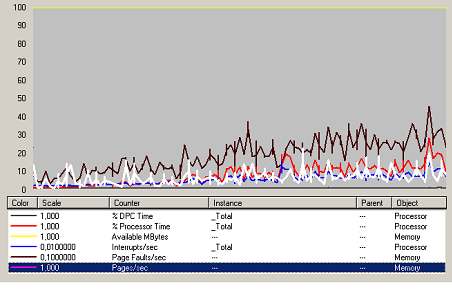
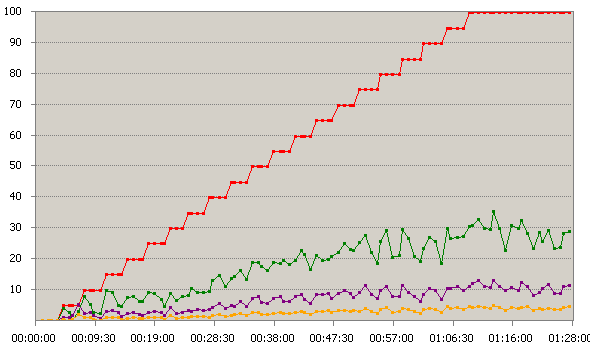
Figure 43 Charge Système Web
Le temps processeur est normal et augmente de façon linéaire à la charge. La courbe des interruptions est de la même forme. La mémoire disponible est très haute ( > 1Go) donc nous pouvons conclure qu’il n’y a eu aucun facteur limitant.
Disque
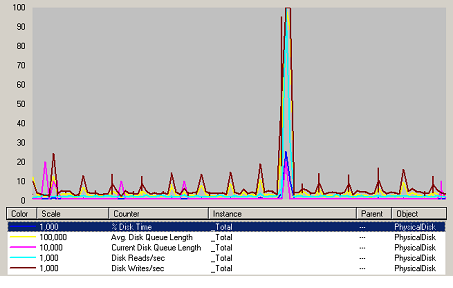
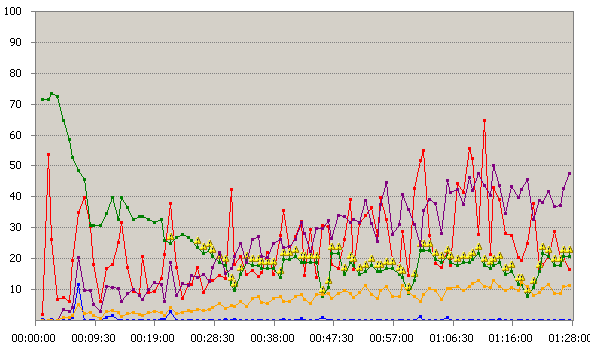
Figure 44 Charge Disque Web
La charge n’a pas influence les performances disques. Le pic au centre de la courbe n’est pas significatif et ne doit pas être interprété.
Réseau
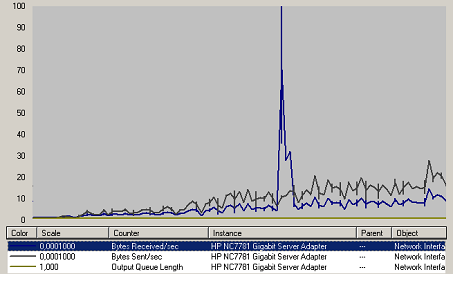
Figure 45 Charge Réseau Web
Le trafic réseau suit la charge des utilisateurs. Nous ne constatons aucune limite sur l’interface réseau.
IIS
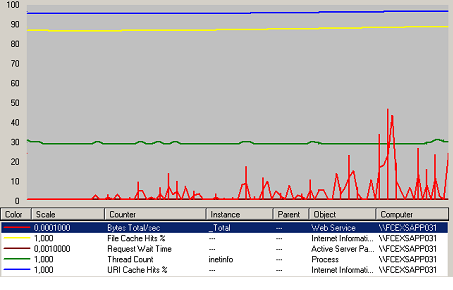
Figure 46 Charge IIS Web
Le serveur WEB n’a aucun problème
ASP.NET
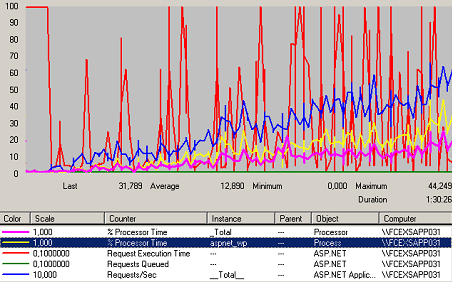
Figure 47 Charge ASP.net Web
# of Exceps Thrown sans changement sur la durée du test donc il n’a pas été mis sur le graphique.
% Time in GC sans changement sur la durée du test donc il n’a pas été mis sur le graphique.
Application Restart sans changement sur la durée du test donc il n’a pas été mis sur le graphique.
WorkerProcessRestart sans changement sur la durée du test donc il n’a pas été mis sur le graphique.
Dans le rapport de STATSPACK, nous voyons que les mesures des pourcentages d’efficacité sont tous proches du maximum. Le temps processeur qui a été utilisé par Oracle, sur la durée du test est de 15 %.
Quelques requêtes sont très consommatrices en ressources avec des Gets per Exec très élevés.
Ces requêtes peuvent être optimisées pour améliorer la montée en charge du serveur Oracle.
Très peu d’attente sur les écritures par des verrous. Donc les ajouts se passent sans problèmes.
Oracle n’a pas été un point bloquant lors de ce test de charge.
Le système HPUX a été que très faiblement utilisé lors de ce test de charge. Le système a supporté parfaitement la charge. Il n’est pas un point de blocage.
| Page |
Test |
Request Total |
AVG Page Time |
| Notations.aspx | Consultation |
966 |
0,083 |
| Notations.aspx | SaisieGrille |
393 |
0,110 |
| notations.aspx | Consultation |
966 |
1,330 |
| notations.aspx | SaisieGrille |
99 |
1,460 |
| login.aspx | Consultation |
483 |
0,039 |
| login.aspx | SaisieGrille |
262 |
0,077 |
| grille_score_ratio.aspx | SaisieGrille |
4 422 |
0,650 |
| Contrepartie.aspx | Consultation |
966 |
0,100 |
| Contrepartie.aspx | SaisieGrille |
262 |
0,081 |
| APPLIXXX/ | SaisieGrille |
131 |
0,005 |
| APPLIXXX/ | Consultation |
483 |
0,006 |
| APPLIXXX.aspx | Consultation |
483 |
0,088 |
| APPLIXXX.aspx | SaisieGrille |
131 |
0,091 |
| APPLIXXX | SaisieGrille |
131 |
0,004 |
| APPLIXXX | Consultation |
483 |
0,006 |
Nous sommes largement en dessous des valeurs demandées pour les temps de réponses du coté utilisateur. La charge maximale n’est pas atteinte.
|
Modèle de charge |
||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Figure 48 Modèle de charge |
||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||
Charge de 100 à 560 utilisateurs donc une simulation de 1000 à 5600 utilisateurs réels.
La charge est modélisée avec des paliers pour laisser le temps au système de se stabiliser.
La charge réseau ne montre pas de limitation du coté client de test.
|
Système |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Figure 49 Charge Système |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Le client utilisé pour les tests a une mémoire vive assez faible (512 Mo) qui a suffit à faire fonctionner le test mais il y a eu le déclenchement des alertes.
Système
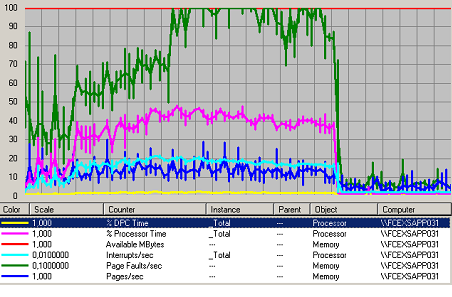
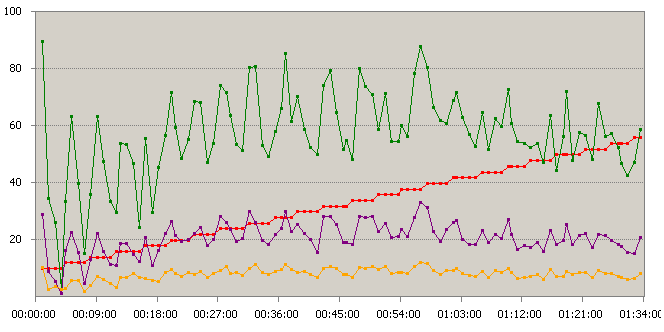
Figure 410 Charge Système Web
Le système Web supporte la charge mais il y a une saturation à partir de 3000 utilisateurs, Nous voyons que le système n’augmente plus sa charge processeur pour répondre au client. La charge actuelle du processeur est de 40 % pour les 3000 utilisateurs. Au dessus de 3000 utilisateurs le nombre de Page Faults/sec augmente d’un coup.
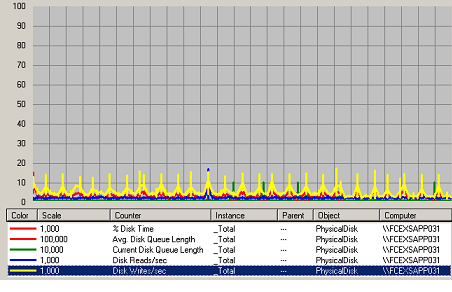
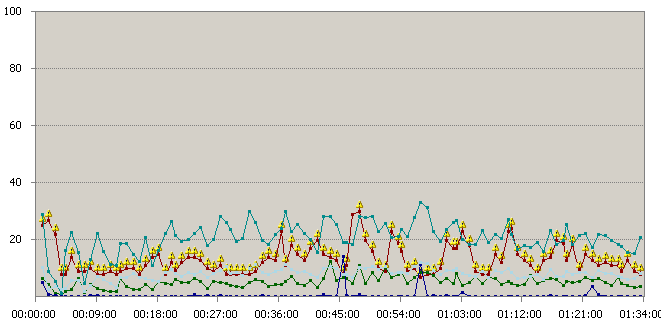
Figure 411 Charge Disque Web
La charge disque est très stable lors des tests. Aucune information ne peut être exploitée par ces compteurs.
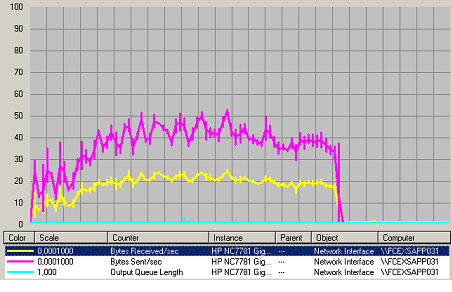
Figure 412 Charge Réseau Web
La charge réseau augmente jusqu’au palier de 2800 personnes sur le serveur. Ensuite elle se stabilise même avec l’augmentation du nombre de client. Ceci montre qu’il y a une saturation. Le nombre d’utilisateur sur le serveur ne doit donc pas dépasser 2600 personnes.
Nous ne sommes pas dans les limites de la carte réseau. Donc ce n’est pas le réseau en lui même qui bloque. Le point de blocage n’est pas sur la carte réseau.
IIS
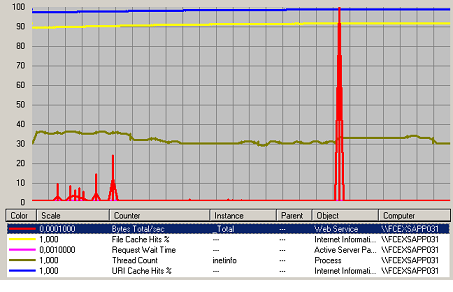
Figure 413 Charge IIS Web
Les serveur Web est utilisé normalement. IIS utilise ses caches pour répondre aux demandes des clients.
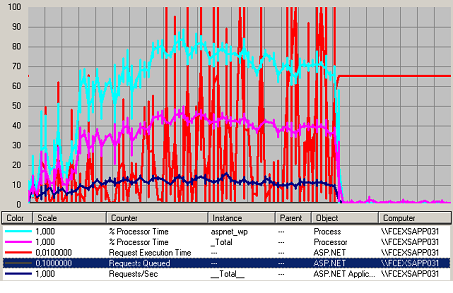
Figure 414 Charge ASP.NET Web
# of Exceps Thrown sans changement sur la durée du test donc il n’a pas été mis sur le graphique.
% Time in GC sans changement sur la durée du test donc il n’a pas été mis sur le graphique.
Application Restart sans changement sur la durée du test donc il n’a pas été mis sur le graphique.
WorkerProcessRestart sans changement sur la durée du test donc il n’a pas été mis sur le graphique.
Le process de aspnet_wp utilise à 80% le temps CPU au cours des phases de tests. Nous notons que cette valeur est le maximum atteint même si nous augmentons la charge. Cette valeur est supérieure à la valeur maximale fixée pour l’utilisation des serveurs. Nous pouvons noter que le temps d’exécution augmente fortement après le palier de 3000 utilisateurs.
Dans le rapport de STATSPACK, nous voyons que les mesures des pourcentages d’efficacité sont tous proches du maximum. Le temps processeur qui a été utilisé par Oracle, sur la durée du test est de 75 %. Donc une charge très importante.
Quelques requêtes sont très consommatrices en ressources avec des Gets per Exec très élevés.
Ces requêtes peuvent être optimisées pour améliorer la montée en charge du serveur Oracle.
Une amélioration par le passage des statistiques et par la réécriture de la requête la plus consommatrice permet de faire passer le compteur Gets per Exec de 169000 à 200. soit une diminution par presque 1000 des accès.
Très peu d’attente sur les écritures par des verrous. Donc les ajouts se passent sans problèmes.
Nous arrivons ici à la limite de la charge sur notre serveur.
Oracle n’a pas été un point bloquant lors de ce test de charge.
| Page |
Test |
Request Total |
AVG Page Time |
| APPLIXXX | Consultation |
1 630 |
0,009 |
| APPLIXXX | SaisieGrille |
456 |
0,007 |
| APPLIXXX.aspx | SaisieGrille |
456 |
0,260 |
| APPLIXXX.aspx | Consultation |
1 630 |
0,340 |
| APPLIXXX/ | Consultation |
1 630 |
0,059 |
| APPLIXXX/ | SaisieGrille |
456 |
0,041 |
| Contrepartie.aspx | SaisieGrille |
912 |
0,410 |
| Contrepartie.aspx | Consultation |
3 260 |
0,590 |
| grille_score_ratio.aspx | SaisieGrille |
15 386 |
5,160 |
| login.aspx | SaisieGrille |
912 |
0,200 |
| login.aspx | Consultation |
1 630 |
0,210 |
| notations.aspx | Consultation |
3 260 |
3,500 |
| notations.aspx | SaisieGrille |
338 |
8,100 |
| Notations.aspx | SaisieGrille |
1 368 |
0,370 |
| Notations.aspx | Consultation |
3 260 |
0,610 |
Les temps de réponses respectent les consignes quand le nombre d’utilisateur est inférieur à 2600 personnes. Aucune page ne mets plus de 10 secondes à s’afficher lors du scénario d’écriture. Et dans la partie consultation les valeurs sont largement en dessous de 5 secondes.
Le serveur Oracle est proche du maximum avec une consommation processeur proche de 75%. La partie Oracle peut être améliorée en ajoutant des processeurs sur le serveur ou en réécrivant les requêtes.
Le serveur Web tient la charge de 2600 utilisateurs
Besoins à déterminer en fonction du test de capacité.
L’objectif étant atteint lors du test de capacité, il n’est pas nécessaire de faire les tests d’évolutivité.
Détermination d’une limite application / matériel
Augmentation de la mémoire
Augmentation de la puissance CPU
Augmentation du nombre de CPU
Augmentation du système disques (nombre de disques, RAID 1 au lieu de 5…)
Détermination d’une limite
Augmentation du nombre de serveurs frontaux
Augmentation du nombre de serveurs applicatifs
Augmentation du nombre de serveurs dorsaux
Distribution des données
Les différents scenarii
Des optimisations peuvent être effectués dans les appels de pages web. Un appel d’URL type http://APPLIXXX/APPLIXXX doit être remplacé par http://APPLIXXX/APPLIXXX/ ceci permet de ne pas avoir une requête de redirection à chaque appel de la page.
Certaines requêtes peuvent être réécrites pour diminuer la charge sur la base de données. Ceci peut être fait en pré calculant certaines valeurs type maximum et en effectuant des requêtes paramétrées. En général, une analyse avec les DBA permet d’optimiser certaines requêtes consommatrices en ressources. Ceci permettra avec la même machine d’atteindre les 3000 utilisateurs.
Une autre optimisation réside dans la mise en place des statistiques sur les bases Oracles.
Enfin pour atteindre le nombre d’utilisateur de 3000 personnes, une machine supplémentaire frontal web doit être ajoutée.
Voici une liste non exhaustive des logiciels de test et de monitoring du marché.
http://www.mercury.com/us/products/performance-center/loadrunner/
http://www.veritest.com/benchmarks/webbench/default.asp
Veritas Netbench
http://www.veritest.com/benchmarks/netbench/default.asp
http://www-306.ibm.com/software/awdtools/suite/
http://www.segue.com/products/load-stress-performance-testing/silkperformer.asp
http://www.radview.com/products/WebLOAD.asp
Microsoft Application Center Test ( ACT)
http://support.microsoft.com/default.aspx?scid=kb;en-us;307492
http://www.microsoft.com/france/msdn/vstudio/vs2005/vsts/default.mspx
http://www.hp.com/products1/unix/operating/wlm/index.html?jumpid=go/wlm
Oracle Enterprise Manager Diagnostics Pack
http://www.oracle.com/technology/products/oem/files/dp.html
Quest Central for Oracle : Performance Analysis for EMC
http://www.quest.com/quest_central_for_oracle/performance–emc.asp
Quest Central for Oracle : Performance Analysis
http://www.quest.com/quest_central_for_oracle/performance_analysis/performance_analysis.asp